서비스 운영이 쉬워지는 AWS 인프라 구축 가이드 를 읽고 실습 한 내용이고 AWS Elastic Load Balancing 생성 방법에 대해서 설명한다.
2020년 03월 10일 기준으로 AWS UI가 변경 될 수 있으니, 참고 하길 바란다.
Elastic Load Balancing
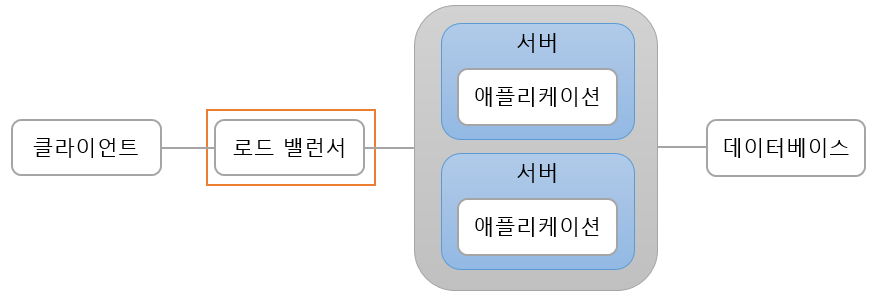
Elastic Load Balancing(ELB, 이하 로드 밸런서)은 위에 그림에 로드 밸런서의 역할을 하는 AWS 서비스 이다. 클라이언트의 요청을 직접 받고 그 요청을 로드 밸런서가 관리하고 있는 서버들에게 여러개의 요청을 골고루 전달해주는 역할을 한다. 단점으로는 AWS에서 로드 밸런서의 기능을 하는 서버를 내부적으로 관리해주기 때문에 우리가 직접 SSH로 접속할 수는 없다.
대상 그룹
대상 그룹(Target Group)은 로드 밸런서가 요청을 전달할 서버들을 묶어둔 개념적인 그룹이며, 이 대상 그룹 내에는 인스턴스(EC2)나 Auto-Scaling 그룹 이 포할될 수 있다.
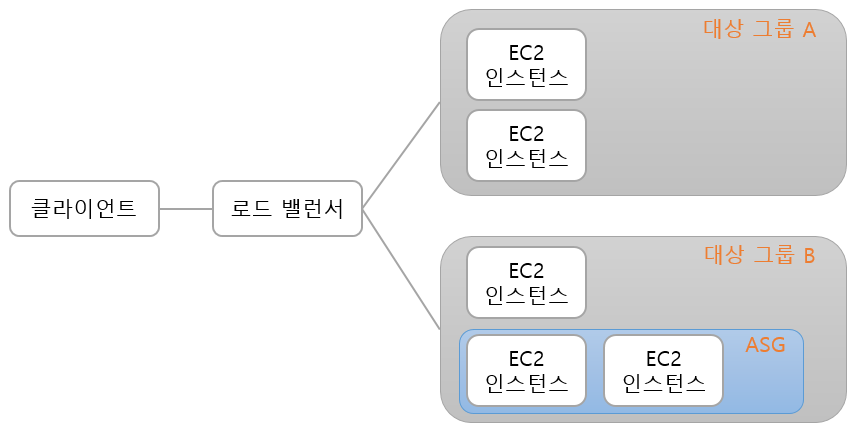
대상 그룹 A에는 EC2 인스턴스 2개대상 그룹 B에는 EC2 인스턴스 3개 그중에 EC2 인스턴스 2개는 Auto Scaling 그룹에 포함대상 그룹 A+대상 그룹 B에 총 EC2 인스턴스 5개로드 밸런서에는대상 그룹 A, B가 등록돼 있기 때문에클라이언트가로드 밸런서로 보낸 요청들을 5개의 EC2 인스턴스가 나눠서 처리한다.
로드 밸런서의 상태 검사
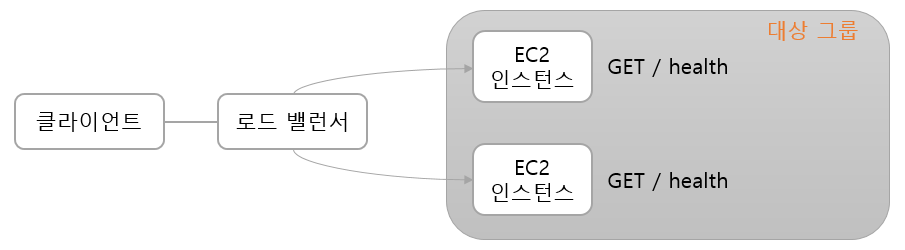
- 정상적으로 동작하고 있는지 확인하기 위해 상태 검사(Health Check) 를 한다.
- 로드 밸런서는 자기가 관리하는 서버들에게 GET/health를 등록해두면 로드 밸런서는 주기적으로 요청을 보내서 상태 코드 200을 확인한다.
- 상태 코드의 주기 또는 비정상 코드를 몇번만에 응답을 해야 하는지도 설정 가능하다.
Auto Scaling 그룹, 대상 그룹, 로드 밸런스 구성
Auto Scaling 그룹을 이용한 실습이다. Auto-Scaling 그룹 관련해서는 참고하길 바란다.
로드 밸런서 생성
EC2 서비스의 로드 밸런싱 -> 로드 밸런서 메뉴 선택한 뒤 로드 밸런서 생성 버튼 클릭
로드 밸런서 유형 선택
일반적으로 HTTP, HTTPS 요청을 받으려고 하므로 Applcation Load Balancer에 생성 버튼 클릭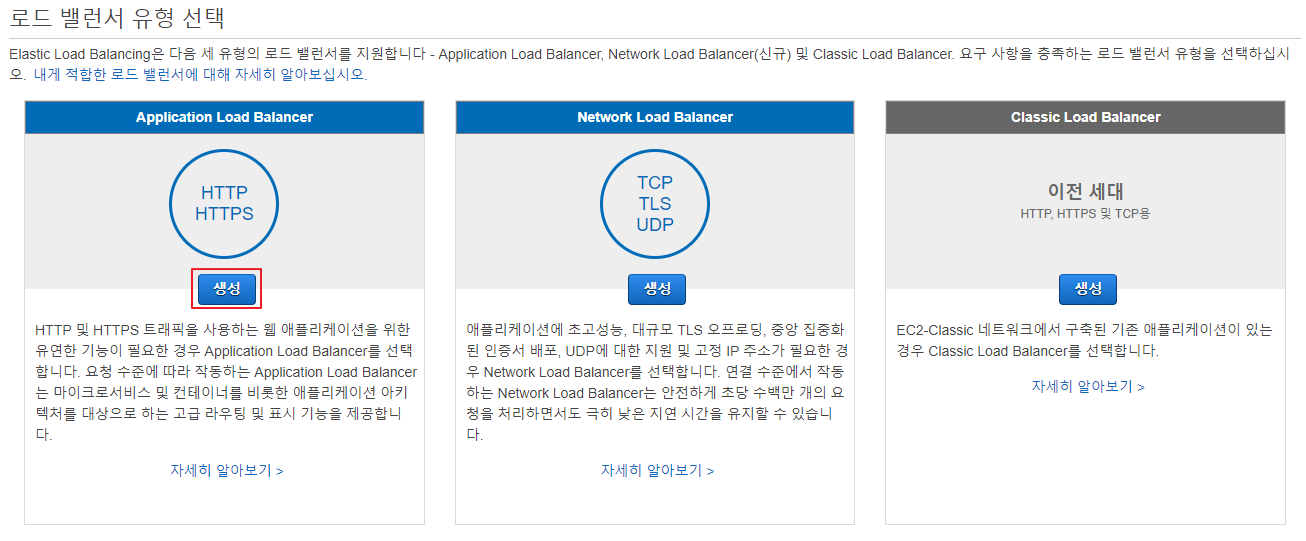
로드 밸런서 구성
이름, 리스너, 가용영역 추가후 다음:보안 설정 구성 버튼 클릭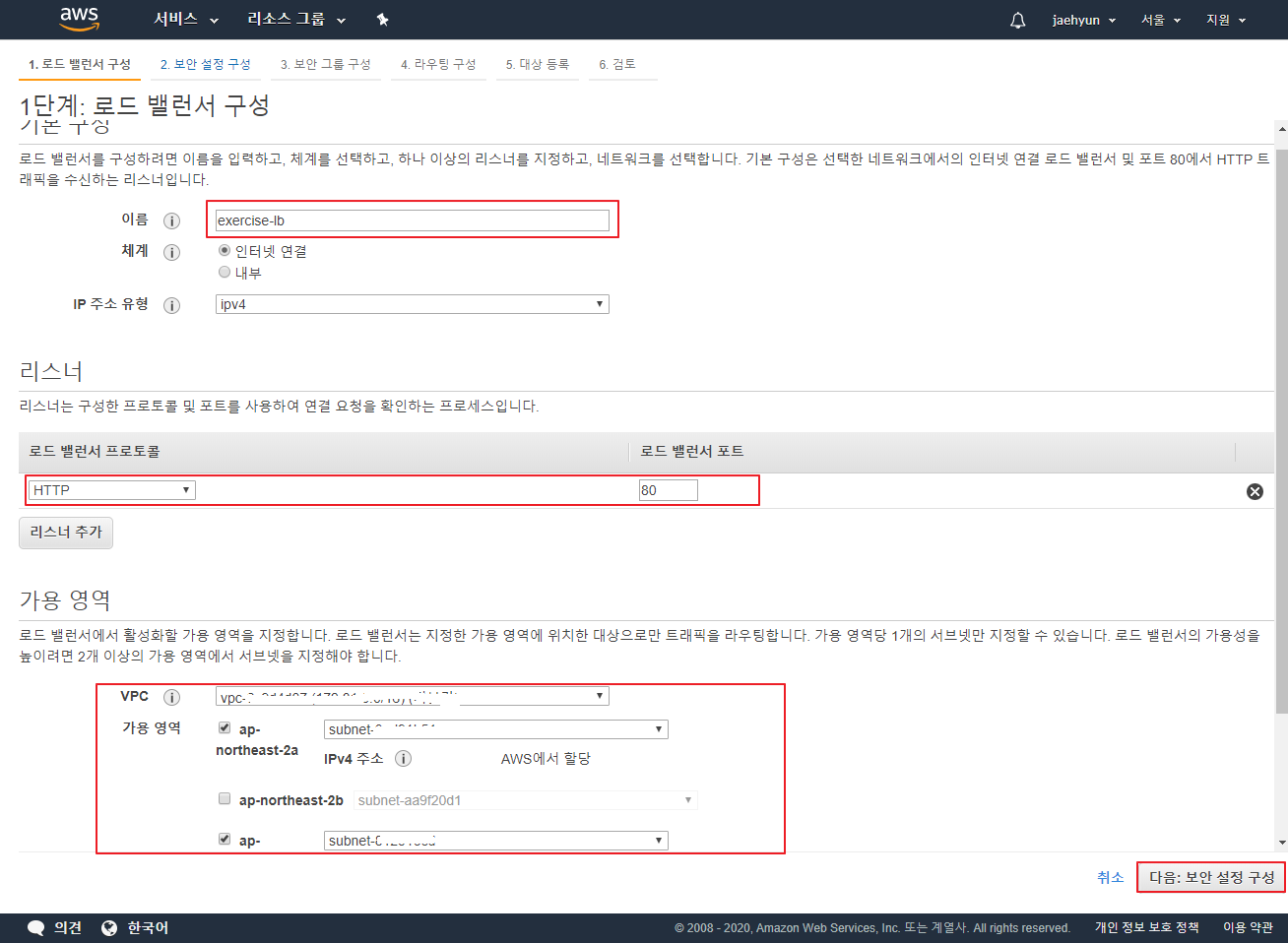
보안 설정 구성
HTTPS 리스너를 추가하지 않아서 생기는 경고이므로 무시하고 다음:보안 설정 구성 버튼 클릭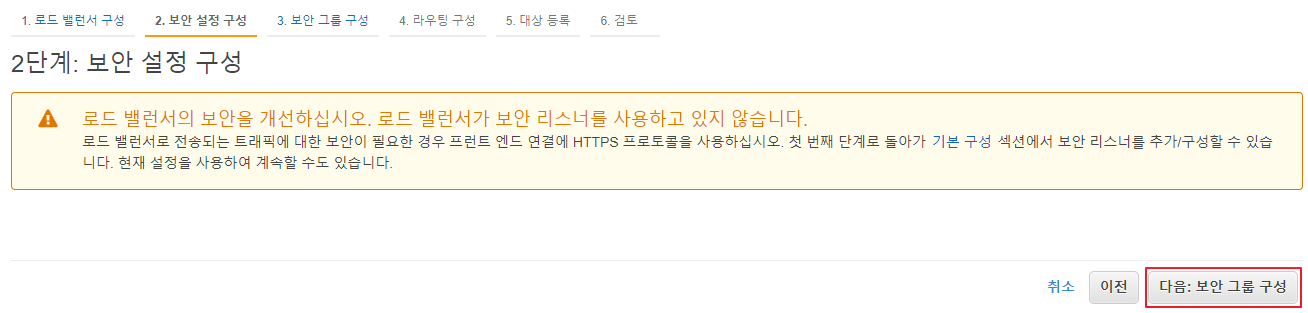
보안 그룹 구성
실습 중에는 HTTP 80포트관련만 받을 것이다. 그러므로 미리 보안 그룹에서 생성한 web 관련 보안 그룹을 선택 후 다음:라우팅 구성 버튼 클릭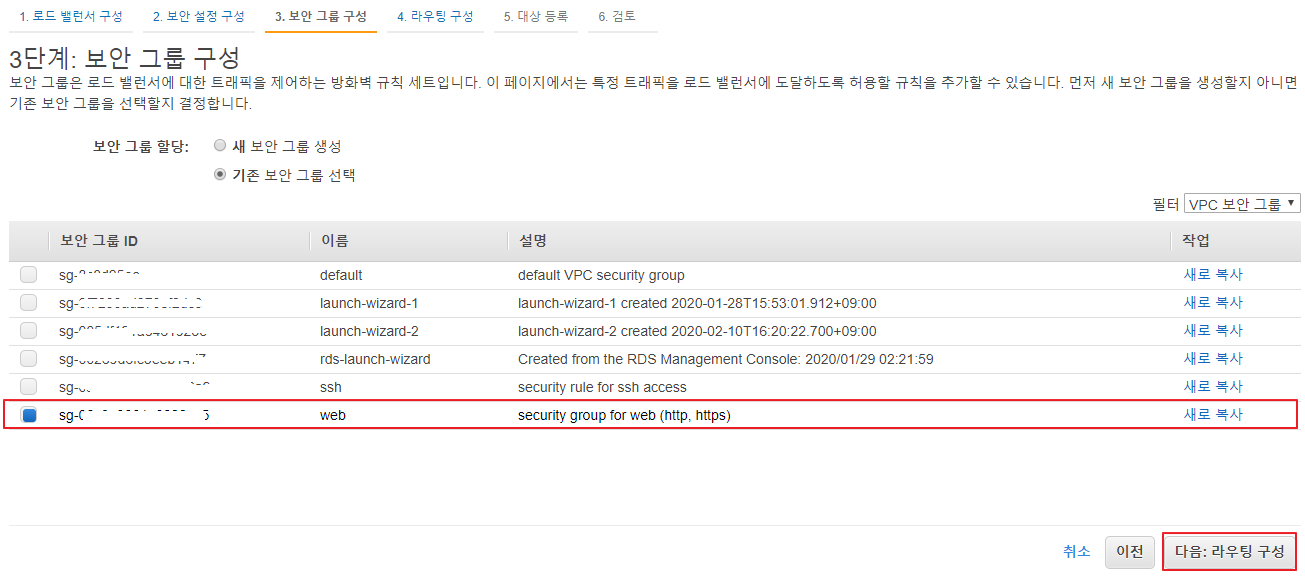
라우팅 등록
- 대상 그룹이 없기 때문에 새 대상 그룹인
exercise-target-group생성 - 상태 검사는 모든 인스턴스 대상으로
/health요청을 주기적으로 날리고 HTTP 상태코드 200을 응답하는지 확인하기 위해 추가 다음:상태 등로버튼 클릭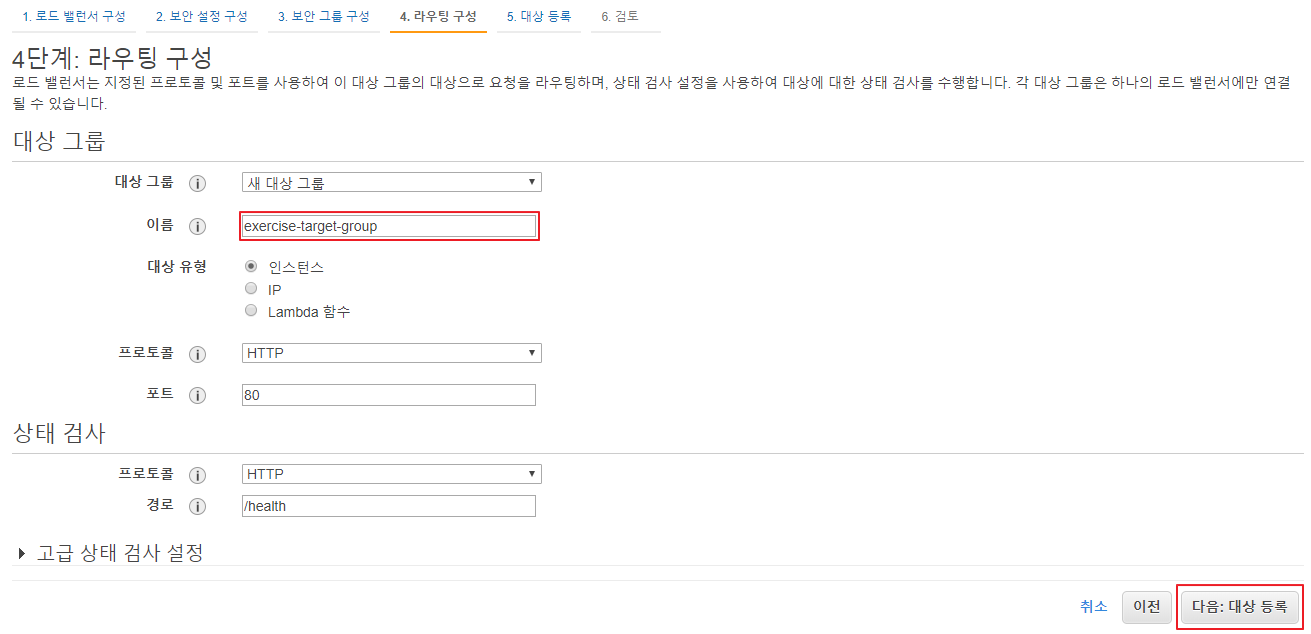
대상 그룹
대상 그룹에 관리할 인스턴스를 추가할 수 있는 화면이며, Auto-Scaling 그룹에서 생성된 인스턴스가 보일 것이다.
인스턴스를 직접 추가할 수 있지만 Auto Scaling 그룹 자체를 대상 그룹에 등록해서 새로운 인스턴스들이 실핼될 때마다 자동으로 대상 그룹에 등록되게 할 것이므로 다음:검토 버튼 클릭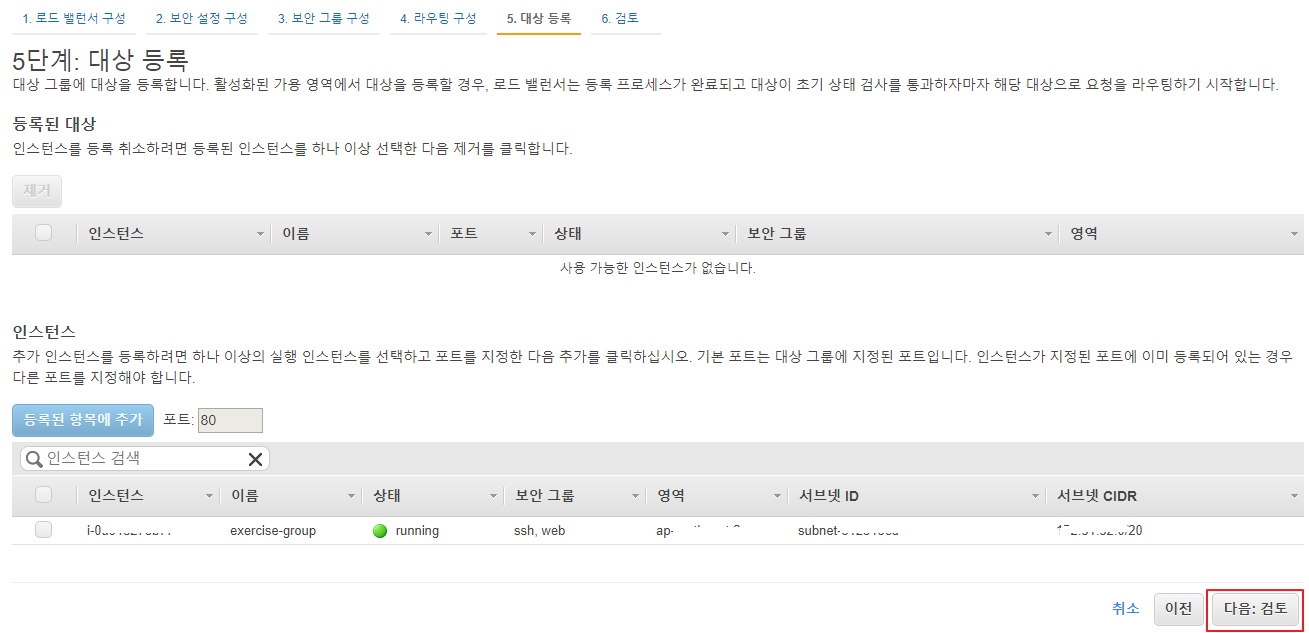
검토
검토 화면에서 앞서 설정한 값이 정상인지 확인 뒤 생성 버튼 클릭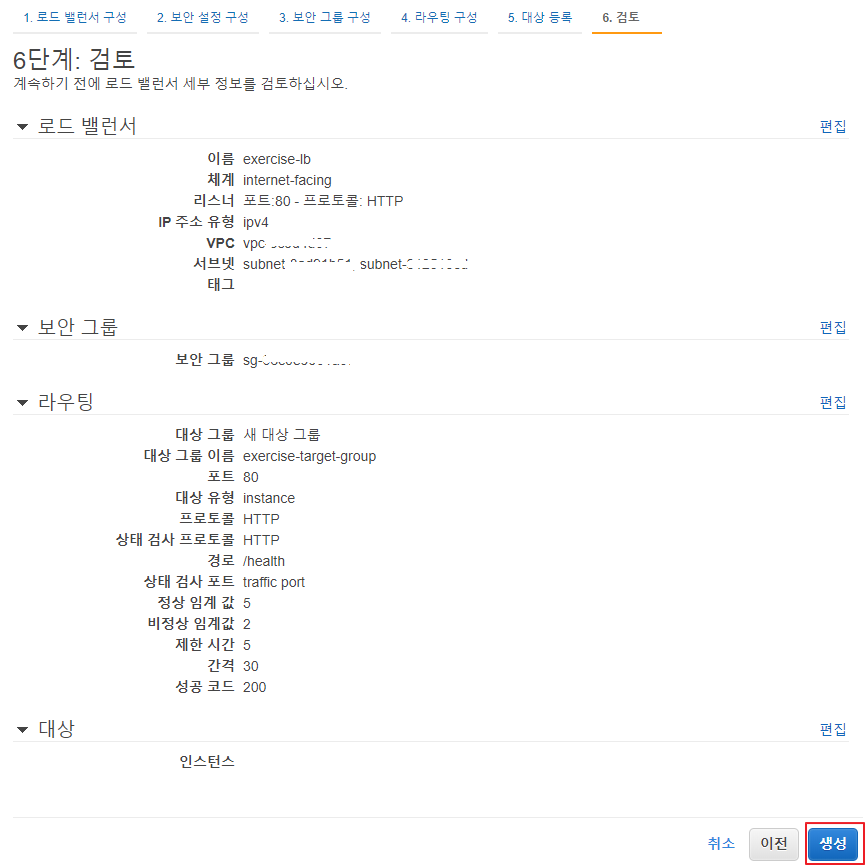
로드 밸런서 생성 확인
로드 밸런싱 -> 로드 밸런서 방금 생성한 로그 밸런서 확인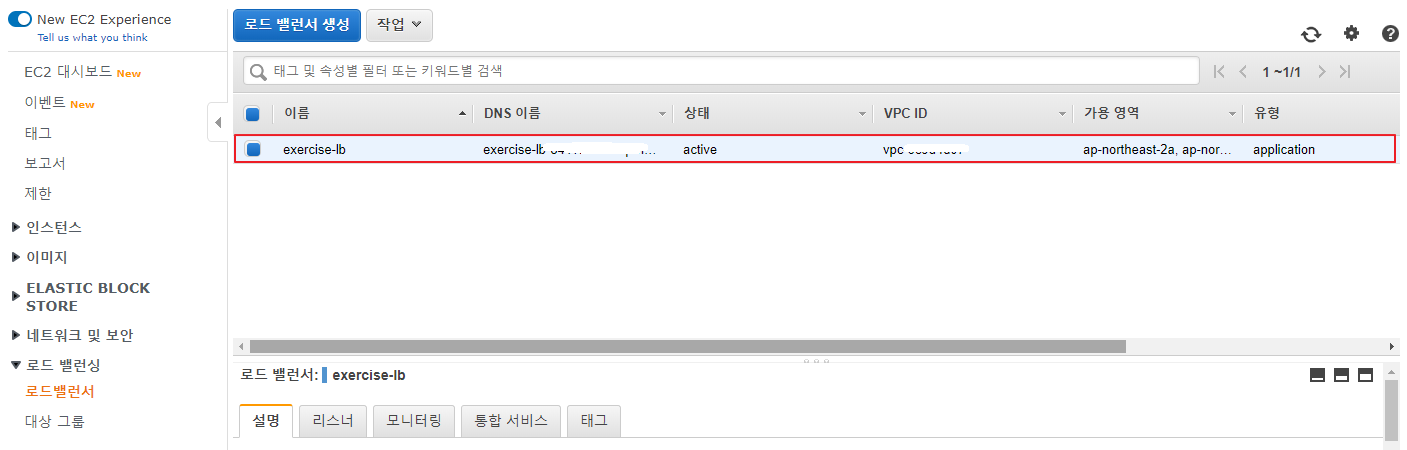
Auto Scaling 그룹에 대상 그룹 추가
Auto Scaling 그룹 -> 세부 정보 탭 -> 편집 버튼 클릭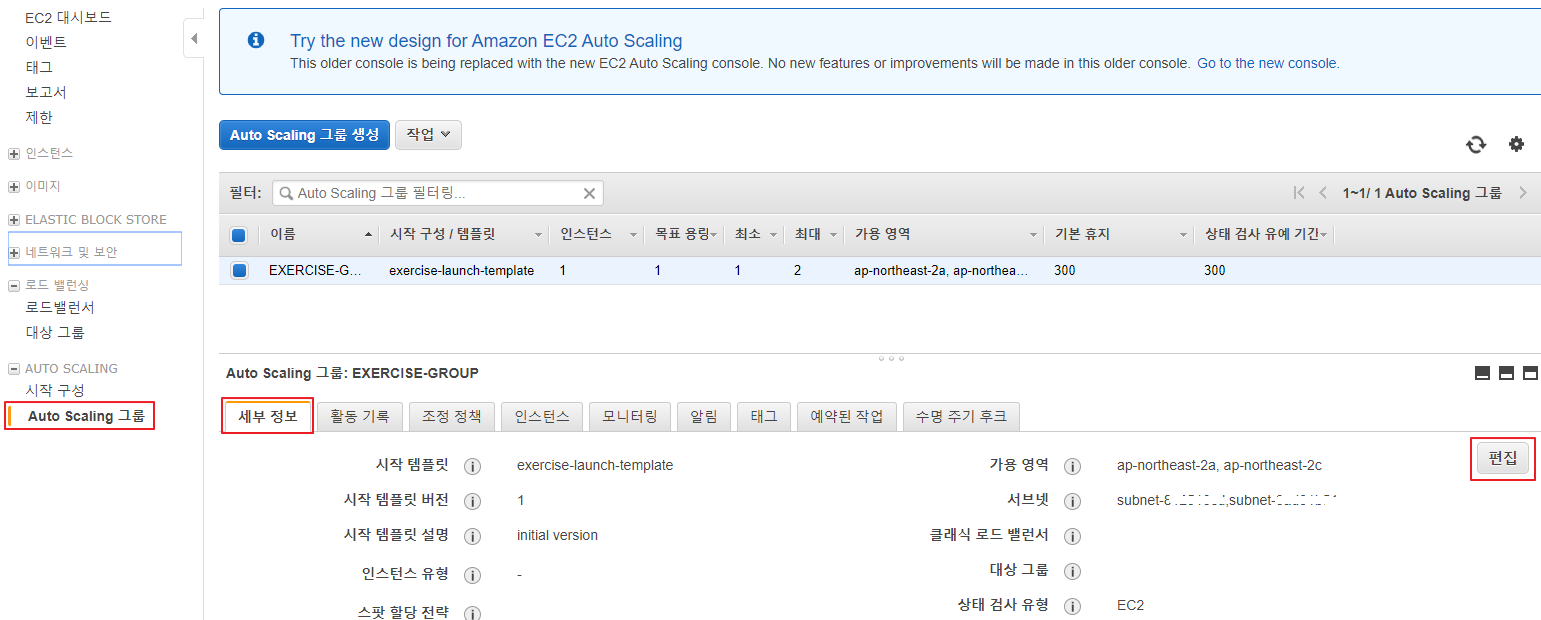
대상 그룹(exercise-target-group) 추가 -> 저장 버튼 클릭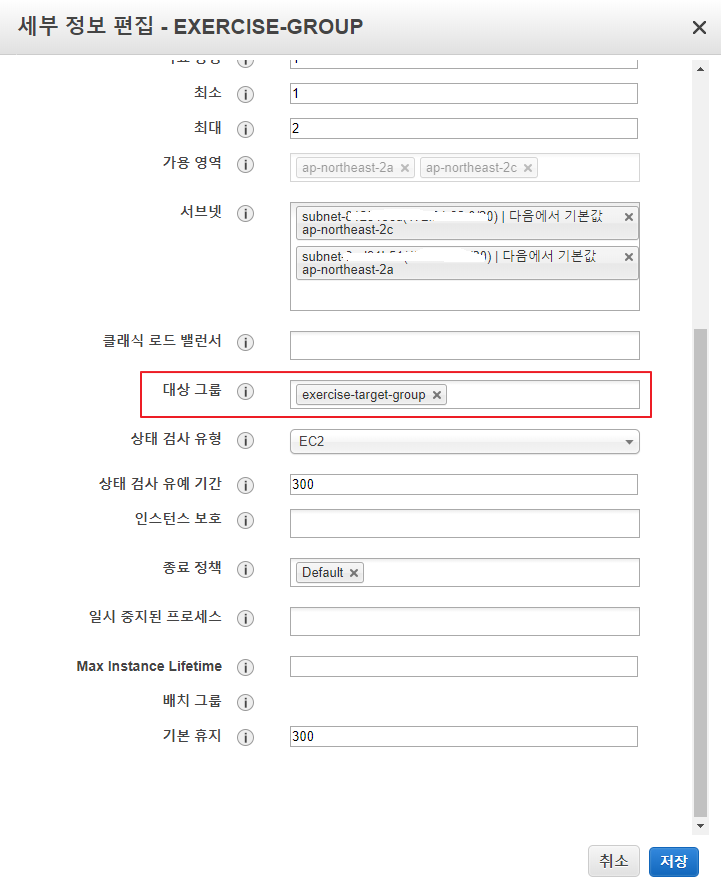
로드 밸런싱 -> 대상 그룹 -> 대상 탭에서 대상 그룹에 Auto Scaling 그룹의 인스턴스가 대상에 등록된것을 확인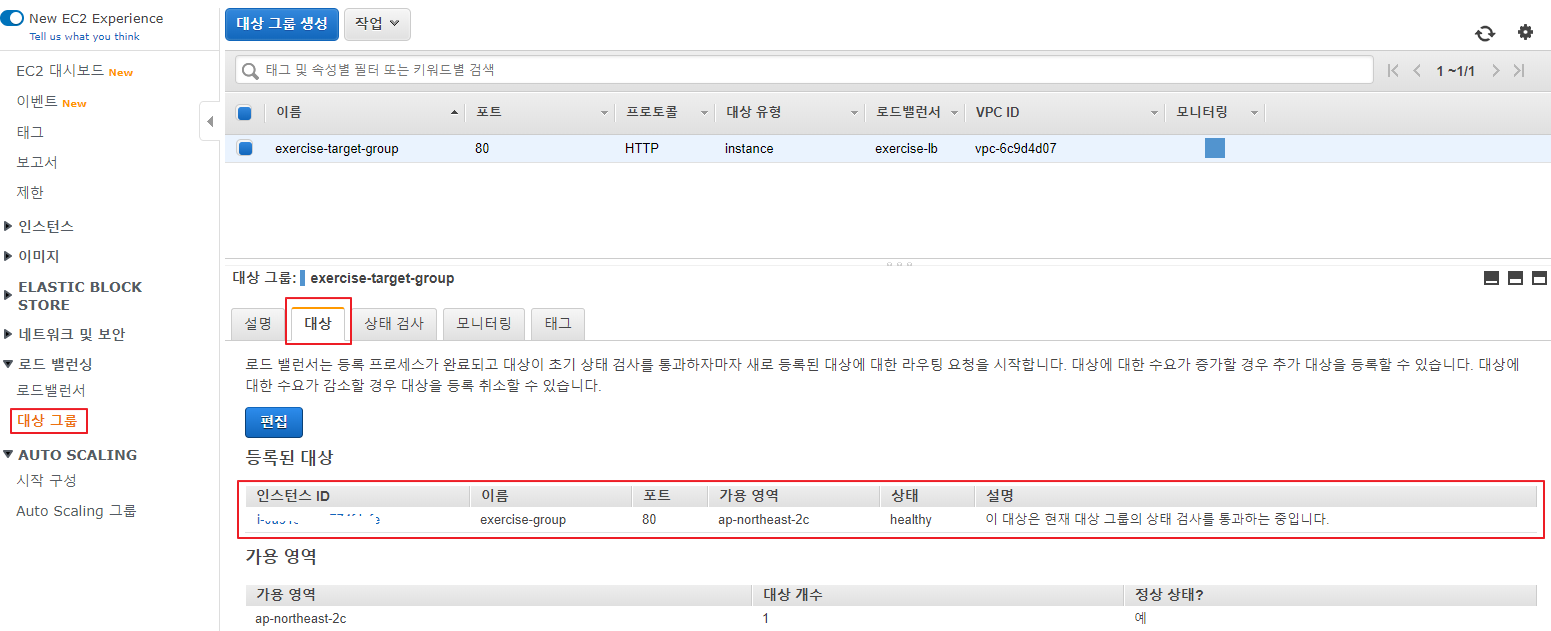
로드 밸런서 작동 확인
로드 밸런싱 -> 로드밸런서 -> exercise-lb 선택 -> DNS 이름 복사 후 접속 확인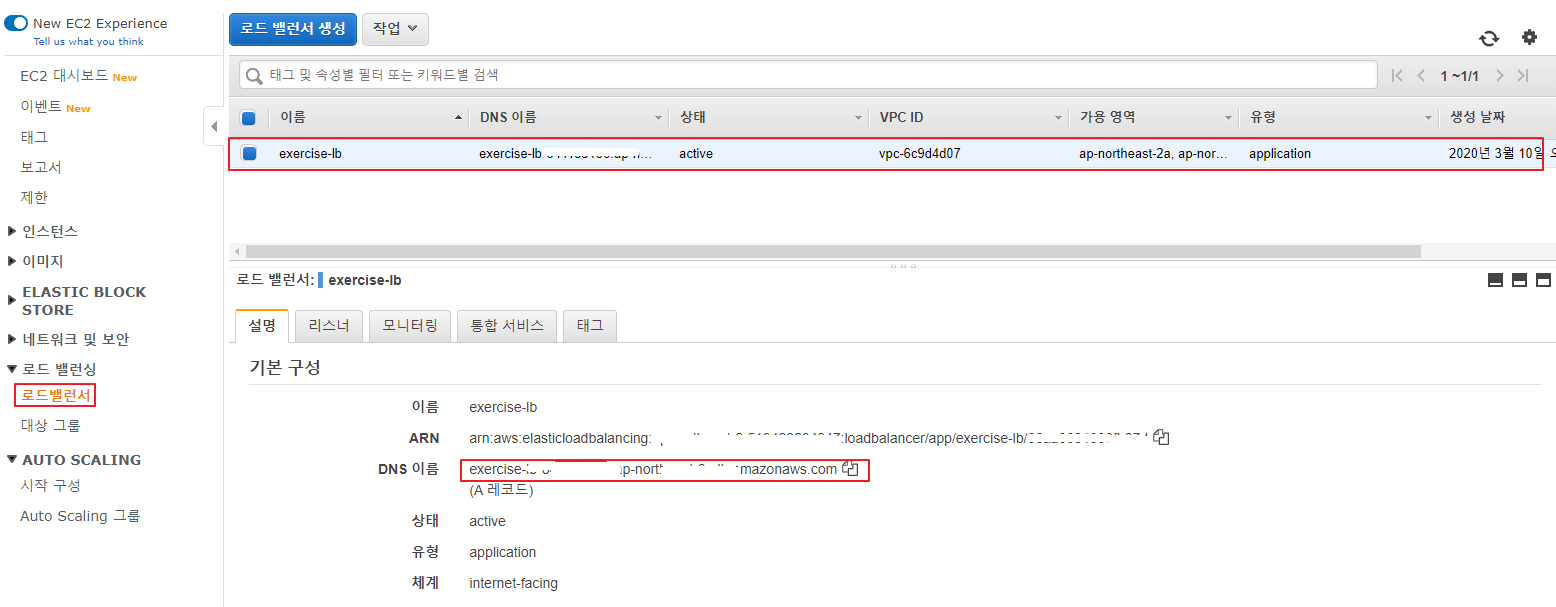

장애 조치 구성
장애 조치란 2개의 시스템이 있을 경우 1개의 시스템에서 장애가 발생시 전체 시스템이 죽는게 아니라 다른 예비 시스템에 즉시 요청을 대신 처리하여 시스템에 문제가 생기지 않도록 하는 것이다.
Auto Scaling 그룹을 이용한 장애 조치
Auto Scaling 그룹과 로드 밸런서를 이용하면 장애 조치를 구현할 수 있는데, 로드 밸런서에서 관리하는 서버 인스턴스들의 상태를 계속해서 파악을 하고 로드 밸런서는 응답이 없는 해당 인스턴스에는 요청을 하지않는디. 결과적으로 클라이언트는 에러 응답을 받지않고 정상적인 응답만 받는다.
Auto Scaling 그룹과 로드 밸런서를 통한 장애 조치
여기서 2개의 서버로 서비스하다가 한 서버 장애가 나는 경우 로드 밸런서가 자동으로 정상적인 서버에만 요청하는지 확인한다.
로드 밸런서 상태 검사 편집
로드 밸런싱 -> 대상 그룹 -> 상태 검사 탭 -> 상태 검사 편집 버튼 클릭
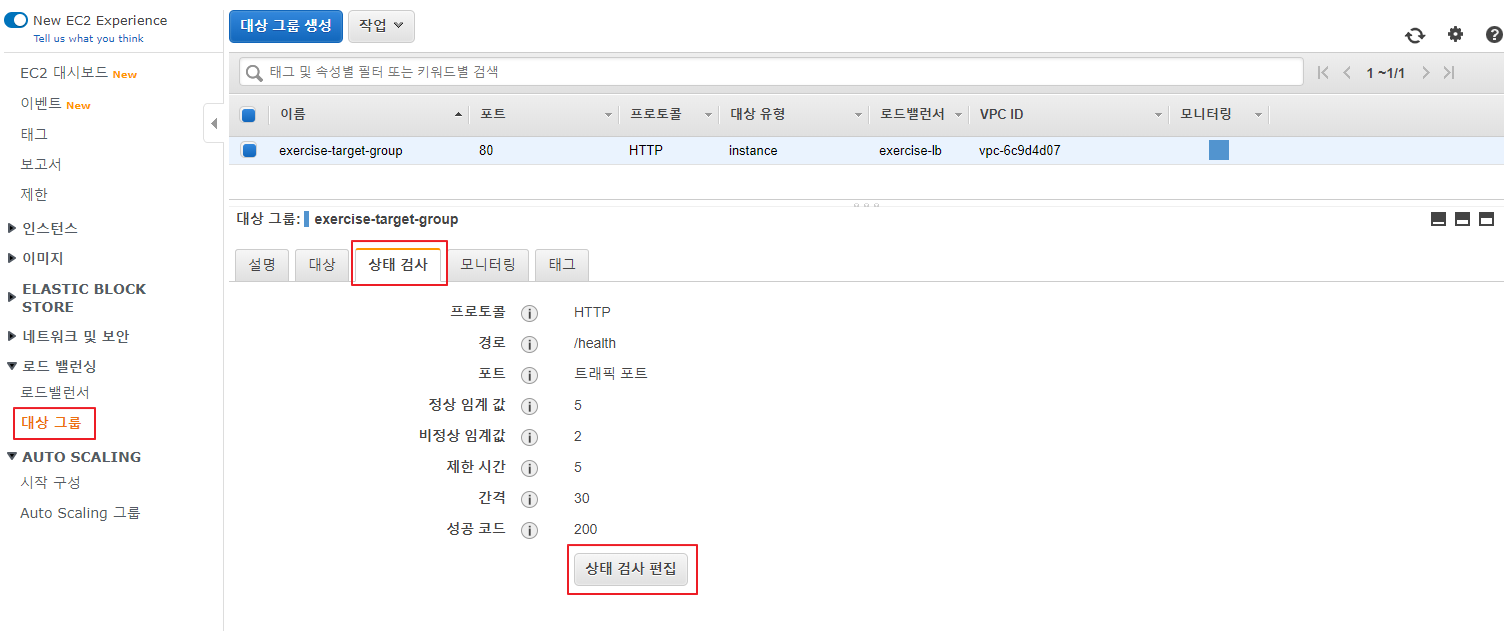
상태값 변경 후 저장 버튼 클릭
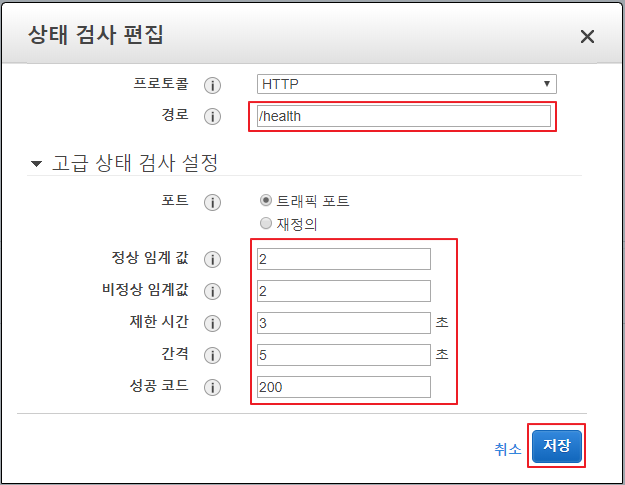
| 항목 | 설명 |
|---|---|
| 경로 | 인스턴스가 정상인지 확인하기 위해 호출할 URL주소 |
| 정상 임계 값 | 연속으로 몇 번 정상 응답을 해야만 정상 상태로 볼 것인지 지정 |
| 비정상 임계 값 | 연속으로 몇 번 비정상 응답을 해야만 정상 상태로 볼 것인지 지정 |
| 제한 시간 | 타임아웃 시간으로 응답이 몇 초 이내로 오지 않을 경우 비정상 응답으로 판단할지 지정 |
| 간격 | 몇 초 간격으로 인스턴스의 상태를 물어볼지 지정하는 항목 |
| 성공 코드 | 어떤 HTTP 응답 코드를 줬을 경우 정상 상태로 판단할 것인지 지정 |
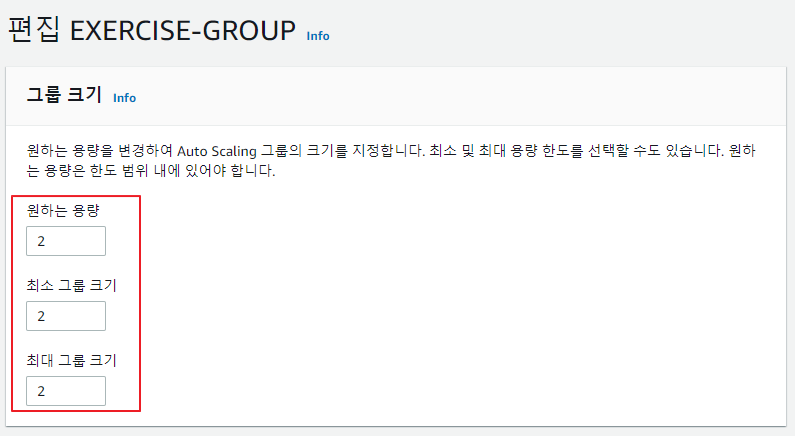
Auto Scaling 원하는 용량, 최소 그룹 크기 변경
AUTO SCALING -> Auto Scaling 그룹 -> 편집 버튼 클릭
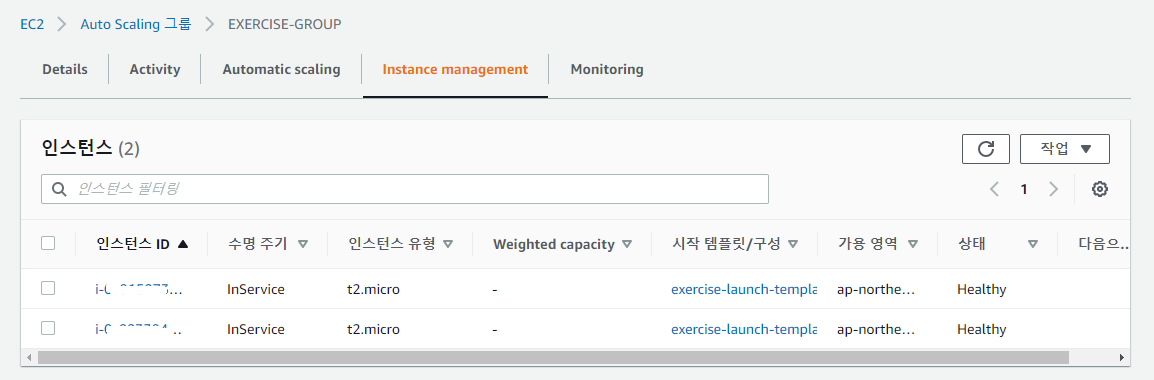
인스턴스 확인
Instance management 탭
두 서버에 SSH 접속 후 실시간 로그 확인
1 | cd /opt/nginx/logs |
장애 발생 처리
A 서버 종료 후 브라우저를 연속으로 새로고침 을 하면 처음에는 상태코드 502가 나오고 우리가 설정한 정상 임계값인 200이 아니므로 B 서버가 요청을 처리한다.


정리
운영 중 Elastic Load Balancing으로 하나의 서버가 장애가 발생했을 경우 다른 서버에 분산할 수 있다는 것을 알았다. 하지만 Elastic Load Balancing만으로는 서버의 개수를 유동적으로 할 수 없다는 단점이 있는데, Auto Scaling 그룹으로 서버의 개수를 유동적으로 할 수 있다는 강점이 생긴다. 하나의 기능보다 AWS는 여러 가 기능을 결합하여 잘 사용하면 더 좋은 서비스를 구현할 수 있다고 생각을 한다.